

[ad_1]
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
Last week, Midjourney, the AI startup building image (and soon video) generators, made a small, blink-and-you’ll-miss-it change to its terms of service related to the company’s policy around IP disputes. It mainly served to replace jokey language with more lawyerly, doubtless case law-grounded clauses. But the change can also be taken as a sign of Midjourney’s conviction that AI vendors like itself will emerge victorious in the courtroom battles with creators whose works comprise vendors’ training data.

The change in Midjourney’s terms of service.
Generative AI models like Midjourney’s are trained on an enormous number of examples — e.g. images and text — usually sourced from public websites and repositories around the web. Vendors assert that fair use, the legal doctrine that allows for the use of copyrighted works to make a secondary creation as long as it’s transformative, shields them where it concerns model training. But not all creators agree — particularly in light of a growing number of.studies showing that models can — and do — “regurgitate” training data.
Some vendors have taken a proactive approach, inking licensing agreements with content creators and establishing “opt-out” schemes for training data sets. Others have promised that, if customers are implicated in a copyright lawsuit arising from their use of a vendor’s GenAI tools, they won’t be on the hook for legal fees.
Midjourney isn’t one of the proactive ones.
On the contrary, Midjourney has been somewhat brazen in its use of copyrighted works, at one point maintaining a list of thousands of artists — including illustrators and designers at major brands like Hasbro and Nintendo — whose works were, or would be, used to train Midjourney’s models. A study shows convincing evidence that Midjourney used TV shows and movie franchises in its training data, as well, from “Toy Story” to Star Wars” to “Dune” to “Avengers.”
Now, there’s a scenario in which courtroom decisions go Midjourney’s way in the end. Should the justice system decide fair use applies, nothing’s stopping the startup from continuing as it has been, scraping and training on copyrighted data old and new.
But it seems like a risky bet.
Midjourney is flying high at the moment, having reportedly reached around $200 million in revenue without a dime of outside investment. Lawyers are expensive, however. And if it’s decided fair use doesn’t apply in Midjourney’s case, it’d decimate the company overnight.
No reward without risk, eh?
Here are some other AI stories of note from the past few days:
AI-assisted ad attracts the wrong kind of attention: Creators on Instagram lashed out at a director whose commercial reused another’s (much more difficult and impressive) work without credit.
EU authorities are putting AI platforms on notice ahead of elections: They’re asking the biggest companies in tech to explain their approach to preventing electoral shenanigans.
Google Deepmind wants your co-op gaming partner to be their AI: Training an agent on many hours of 3D game play made it capable of performing simple tasks phrased in natural language.
The problem with benchmarks: Many, many AI vendors claim their models have the competition met or beat by some objective metric. But the metrics they’re using are flawed, often.
AI2 scores $200M: AI2 Incubator, spun out of the nonprofit Allen Institute for AI, has secured a windfall $200 million in compute that startups going through its program can take advantage of to accelerate early development.
India requires, then rolls back, gov approval for AI: India’s government can’t seem to decide what level of regulation is appropriate for the AI industry.
Anthropic launches new models: AI startup Anthropic has launched a new family of models, Claude 3, that it claims rivals OpenAI’s GPT-4. We put the flagship model (Claude 3 Opus) to the test, and found it impressive — but also lacking in areas like current events.
Political deepfakes: A study from the Center for Countering Digital Hate (CCDH), a British nonprofit, looks at the growing volume of AI-generated disinformation — specifically deepfake images pertaining to elections — on X (formerly Twitter) over the past year.
OpenAI versus Musk: OpenAI says that it intends to dismiss all claims made by X CEO Elon Musk in a recent lawsuit, and suggested that the billionaire entrepreneur — who was involved in the company’s co-founding — didn’t really have that much of an impact on OpenAI’s development and success.
Reviewing Rufus: Last month, Amazon announced that it’d launch a new AI-powered chatbot, Rufus, inside the Amazon Shopping app for Android and iOS. We got early access — and were quickly disappointed by the lack of things Rufus can do (and do well).
More machine learnings
Molecules! How do they work? AI models have been helpful in our understanding and prediction of molecular dynamics, conformation, and other aspects of the nanoscopic world that may otherwise take expensive, complex methods to test. You still have to verify, of course, but things like AlphaFold are rapidly changing the field.
Microsoft has a new model called ViSNet, aimed at predicting what are called structure-activity relationships, complex relationships between molecules and biological activity. It’s still quite experimental and definitely for researchers only, but it’s always great to see hard science problems being addressed by cutting-edge tech means.
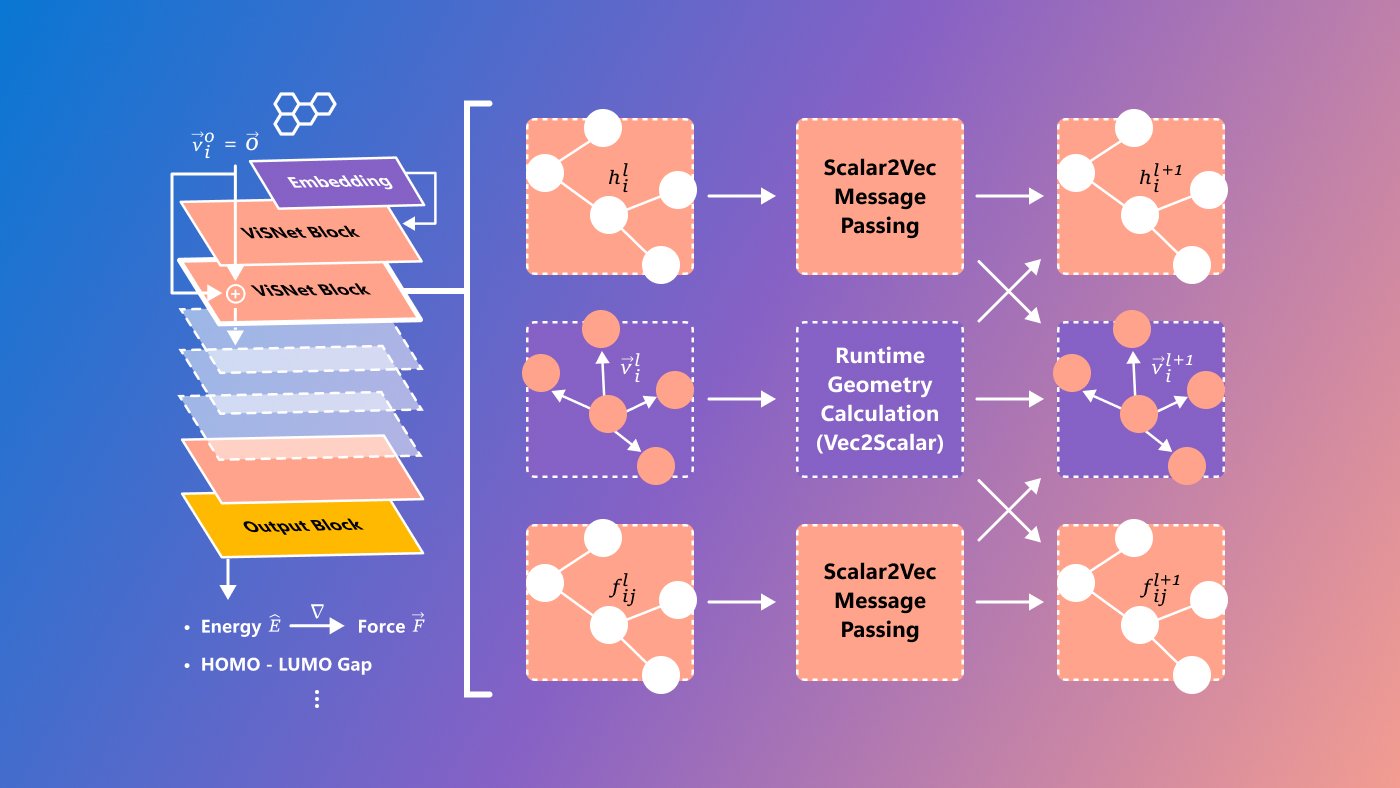
Image Credits: Microsoft
University of Manchester researchers are looking specifically at identifying and predicting COVID-19 variants, less from pure structure like ViSNet and more by analysis of the very large genetic datasets pertaining to coronavirus evolution.
“The unprecedented amount of genetic data generated during the pandemic demands improvements to our methods to analyze it thoroughly,” said lead researcher Thomas House. His colleague Roberto Cahuantzi added: “Our analysis serves as a proof of concept, demonstrating the potential use of machine learning methods as an alert tool for the early discovery of emerging major variants.”
AI can design molecules too, and a number of researchers have signed an initiative calling for safety and ethics in this field. Though as David Baker (among the foremost computational biophysicists in the world) notes, “The potential benefits of protein design far exceed the dangers at this point.” Well, as a designer of AI protein designers he would say that. But all the same, we must be wary of regulation that misses the point and hinders legitimate research while allowing bad actors freedom.
Atmospheric scientists at the University of Washington have made an interesting assertion based on AI analysis of 25 years of satellite imagery over Turkmenistan. Essentially, the accepted understanding that the economic turmoil following the fall of the Soviet Union led to reduced emissions may not be true — in fact, the opposite may have occurred.

AI helped find and measure the methane leaks shown here.
“We find that the collapse of the Soviet Union seems to result, surprisingly, in an increase in methane emissions.,” said UW professor Alex Turner. The large datasets and lack of time to sift through them made the topic a natural target for AI, which resulted in this unexpected reversal.
Large language models are largely trained on English source data, but this may affect more than their facility in using other languages. EPFL researchers looking at the “latent language” of LlaMa-2 found that the model seemingly reverts to English internally even when translating between French and Chinese. The researchers suggest, however, that this is more than a lazy translation process, and in fact the model has structured its whole conceptual latent space around English notions and representations. Does it matter? Probably. We should be diversifying their datasets anyway.
[ad_2]
Source link






